Image to Text Instantly.
Advanced pre-processing pipeline for high-accuracy text extraction. No data ever leaves your browser.

Hello, this is the
extracted content.
[Accuracy: 99.4%]
Recognised content will appear here.
Use cases
Extract text from any image
From scanned documents to screenshots, the OCR engine handles them all — right in your browser.
Physical documents
Extract text from scanned letters, invoices, or printed forms without retyping a single word.
Screen captures
Pull text from error messages, UI screenshots, or chat exports into a copyable format.
Financial records
Digitise receipts, utility bills, or bank statements for easy record keeping or expense tracking.
Business cards
Read names, emails, and phone numbers off business cards or ID documents instantly.
Printed text
Convert printed book pages or typed notes into searchable, editable plain text.
Images with code
Recover code shared as a screenshot so you can copy, edit, or run it without manual retyping.
FAQ
Frequently asked questions
Everything you need to know about image-to-text extraction.
Visual guide
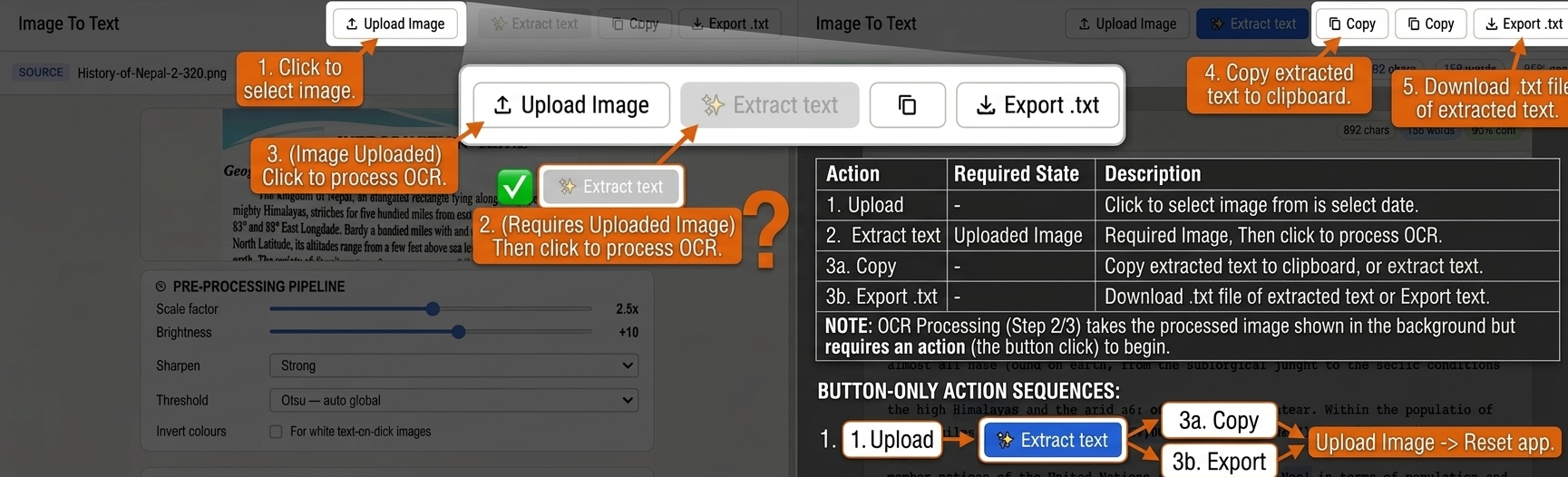
See image-to-text in action
Upload an image, apply preprocessing, and let OCR turn it into editable text — all in your browser.
More free tools